Digital-Ready Tax Law (Digitaltaugliches Steuerrecht)
Funding: German Federal Ministry of Finance (BMF)
Partners: LMUDigiTax (Ludwig Maximilian University of Munich)
Status: Active
Working together with the Center for Digitalization of Tax Law at Ludwig Maximilian University of Munich (LMUDigiTax) and funded by the German Federal Ministry of Finance, we are conducting the study “Digital-Ready Tax Law” (Digitaltaugliches Steuerrecht). The study builds upon an existing partnership in which hackathons have already been organized, focusing on the formalization of tax law provisions using low/no-code tools and legislative drafting that conforms to principles of digital execution.
The project pursues the goal of identifying and systematically analyzing national and international initiatives on human- and machine-readable law (“Rules as Code”/”Law as Code”). This includes developing both statutory and constitutional requirements for a legal format that can be processed equally by humans and machines. Particular attention is given to administrative regulations with discretionary scope and provisions that use indeterminate legal concepts.
Our research systematically examines how modern technologies, such as Natural Language Processing and Large Language Models, can support and improve legislative processes. Through different work packages, viable future scenarios are being developed and evaluated regarding their practical feasibility. Currently, proof-of-concept applications are being developed to demonstrate how AI capabilities could be integrated into legislative workflows while evaluating the reliability, accuracy, and completeness of model-generated results.
1) AI-supported legislative drafting
Interviews conducted with legislative drafters as part of the study revealed several structural problems in everyday work. Particularly burdensome was the significant time pressure, which led to shortened coordination processes and increased risk of errors. Moreover, draft legislation is predominantly created through the exchange of individual documents via email, while digital tools are rarely used. The digital feasibility of new regulations is often considered too late, resulting in the loss of important perspectives.
In response to these challenges, we developed the prototype “LegisLLM”. The application assists drafters using generative AI from the initial political task through to the first legislative draft. The system operates with a sequence of specialized LLM queries, where each step uses the outputs of the previous one as input and is enriched with structured legal data. Norm identification occurs either directly via the language model or through a multi-stage process that extracts relevant provisions from legal databases and filters hierarchically from statutes through sections to specific paragraphs. This processed regulatory context is then used in subsequent generation steps to create various regulatory alternatives, evaluate them from a legal perspective, and finally transform them into the formal structures of amendment commands and drafting documents. Each phase is optimized through domain-specific prompting and the integration of legal terminology.
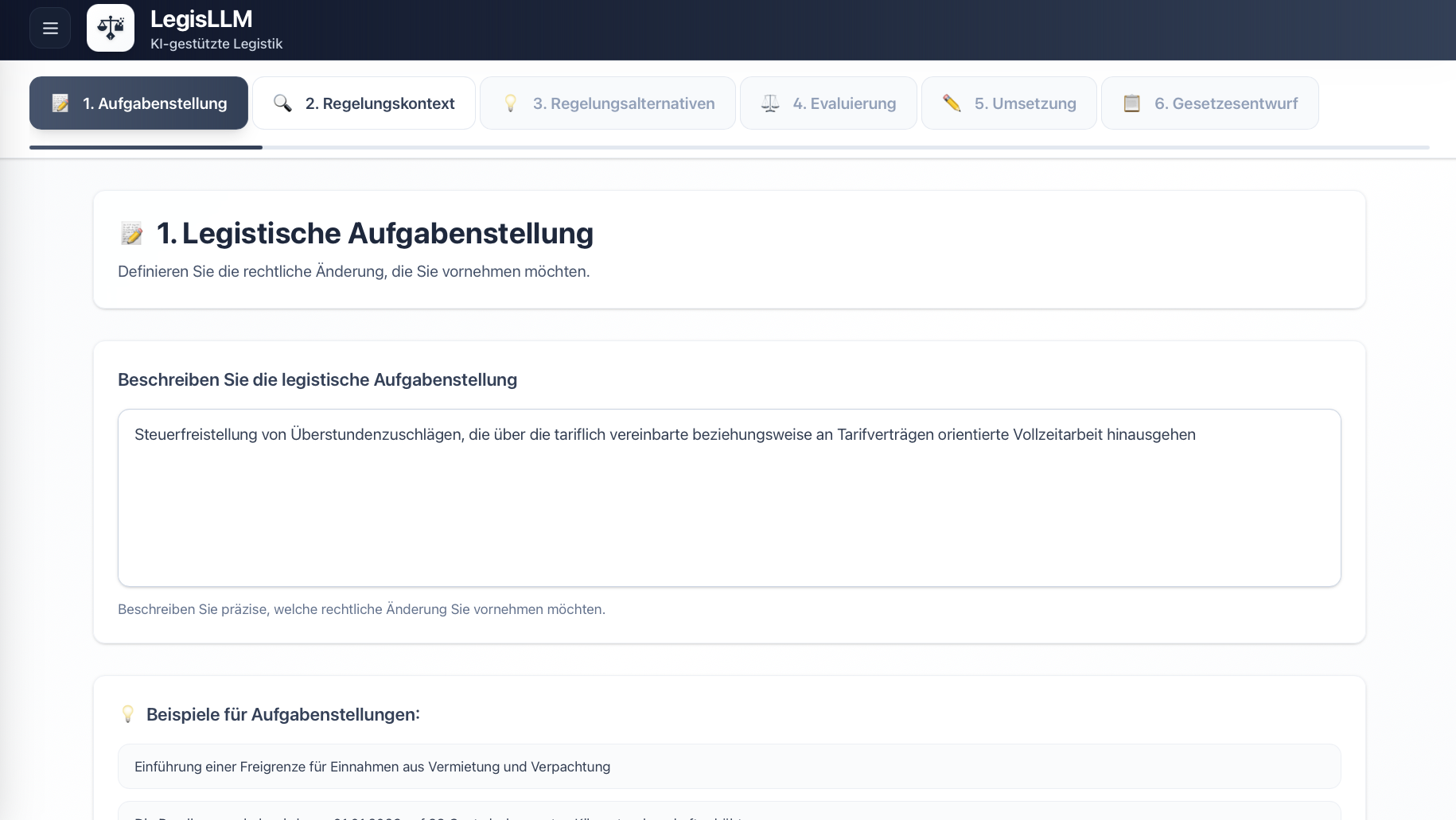
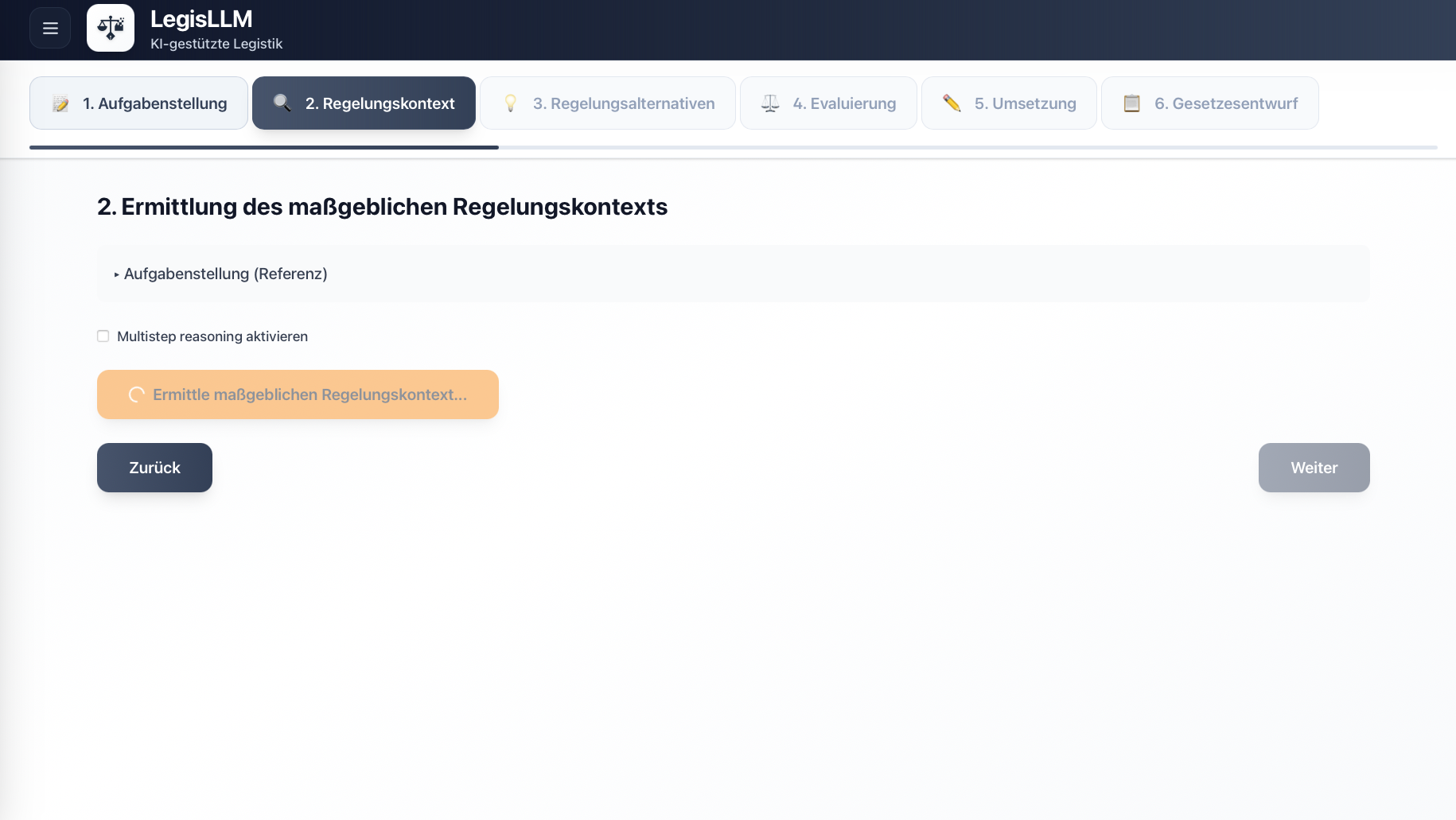
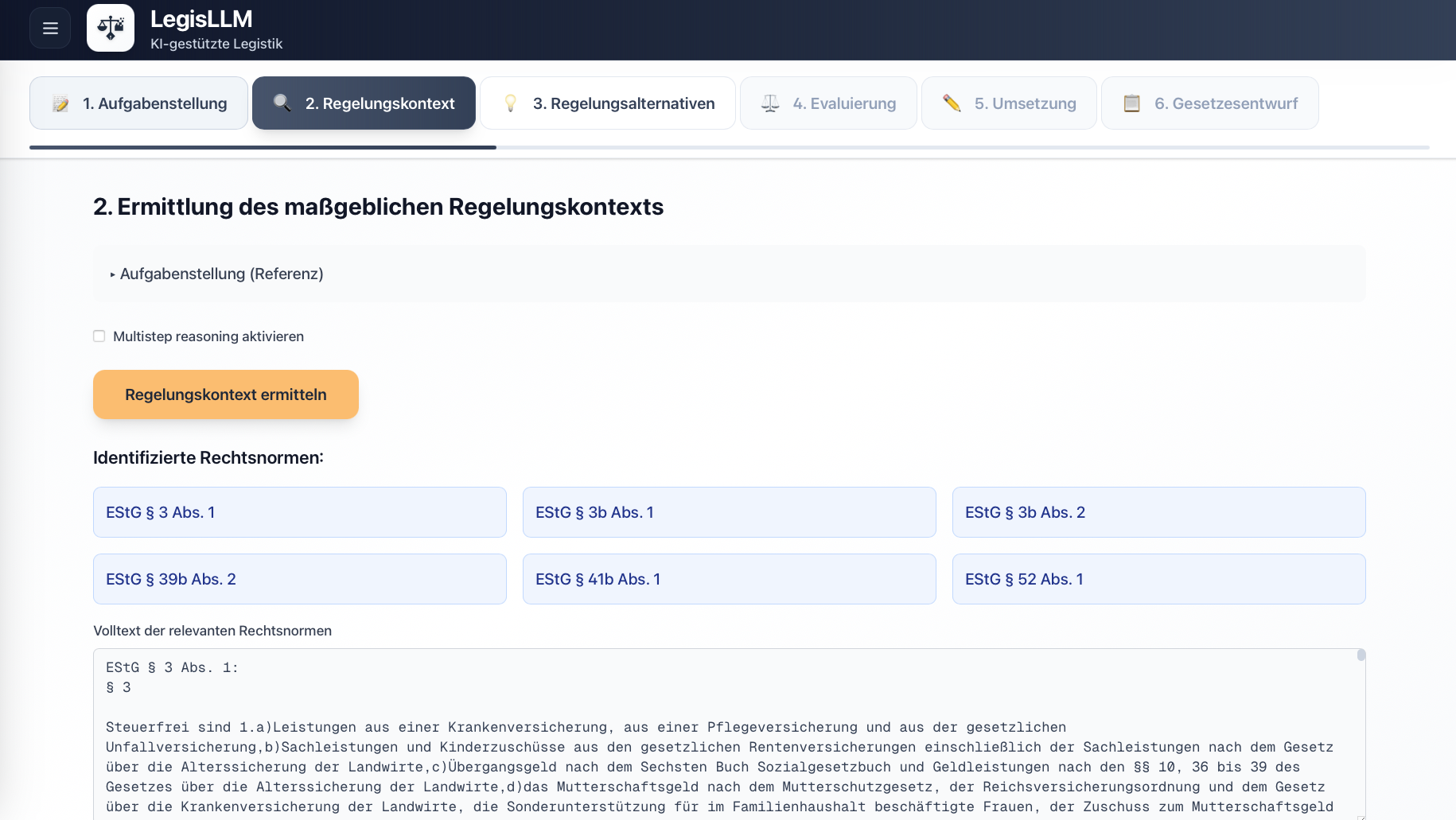
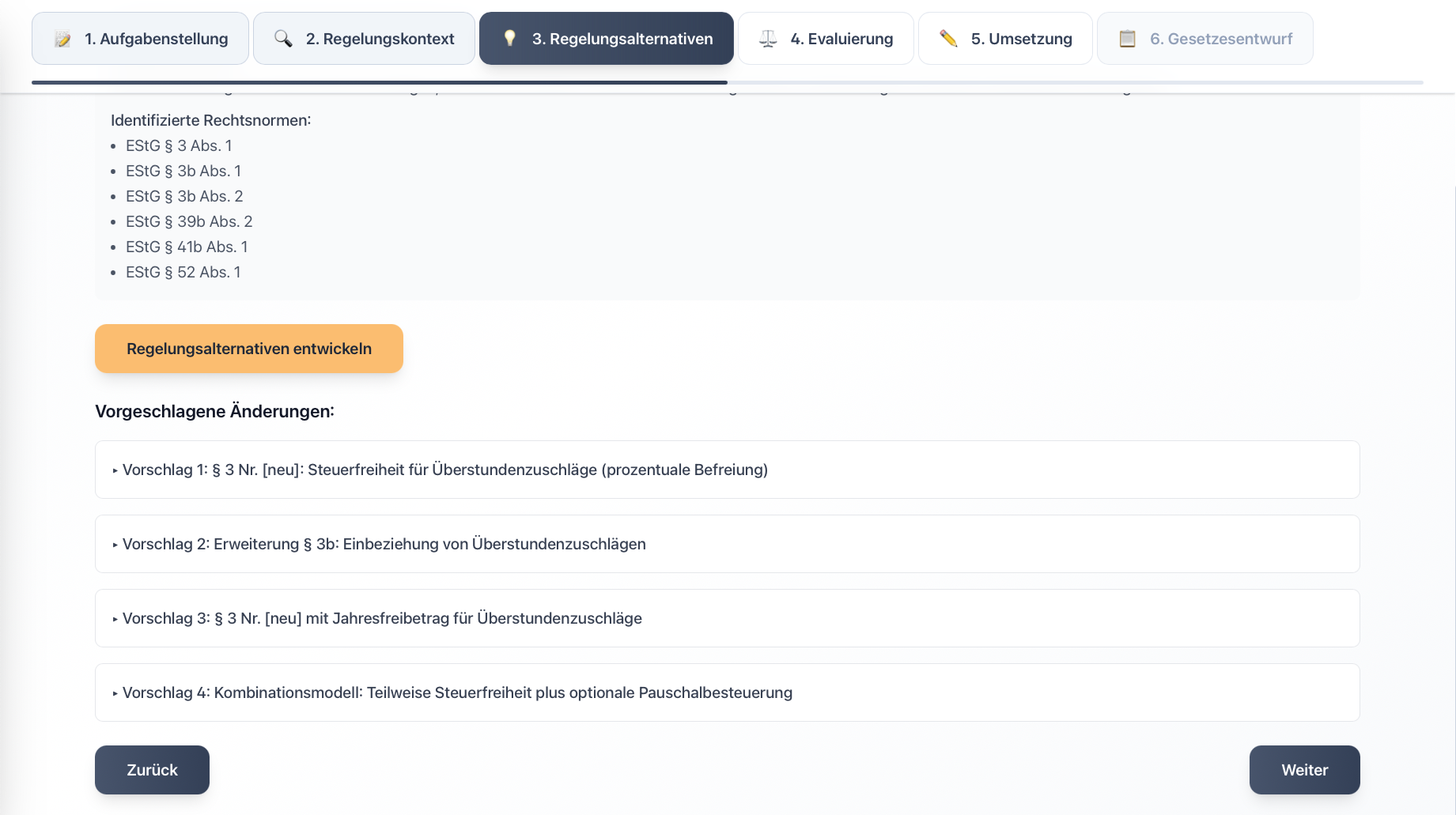
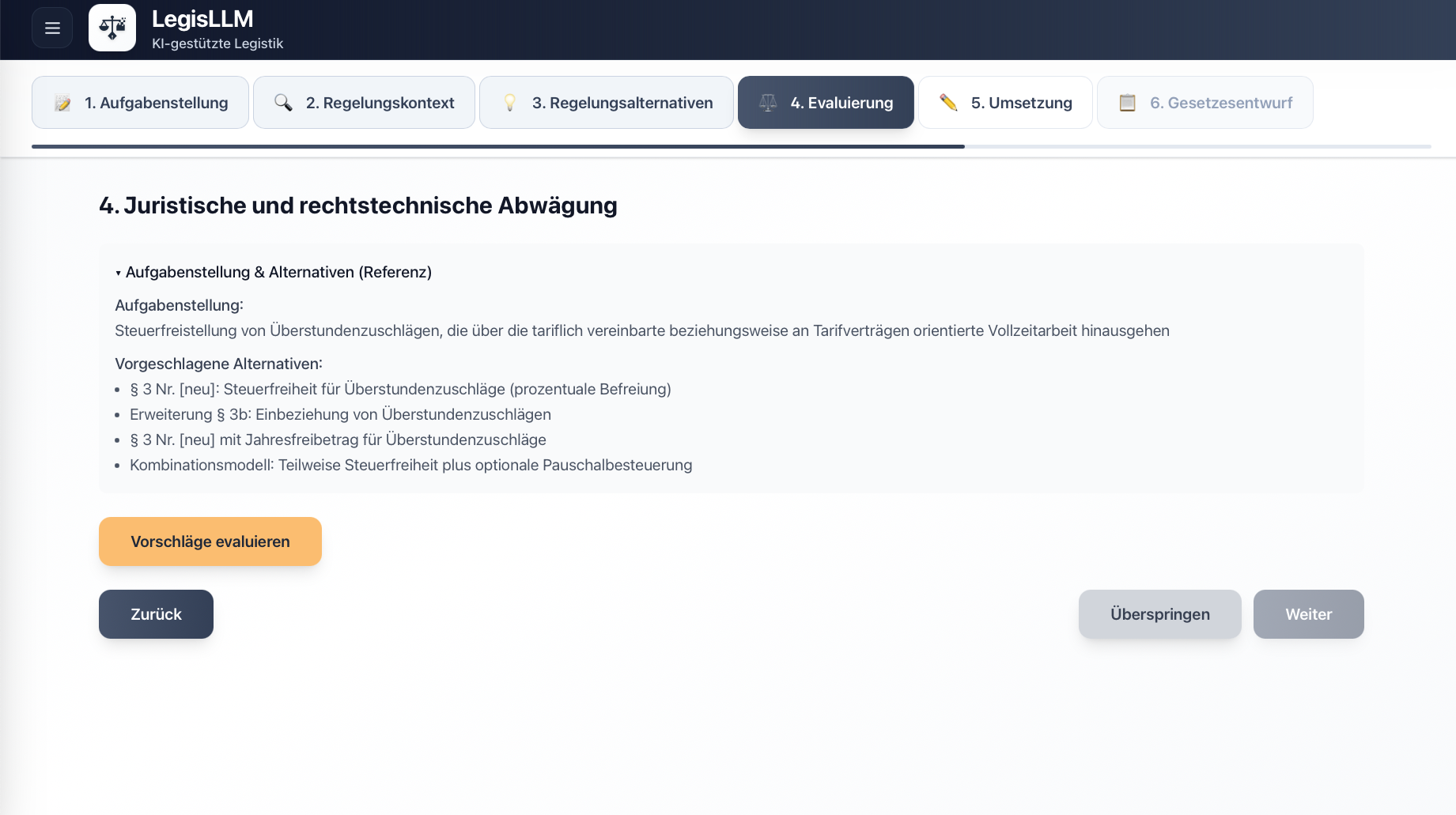
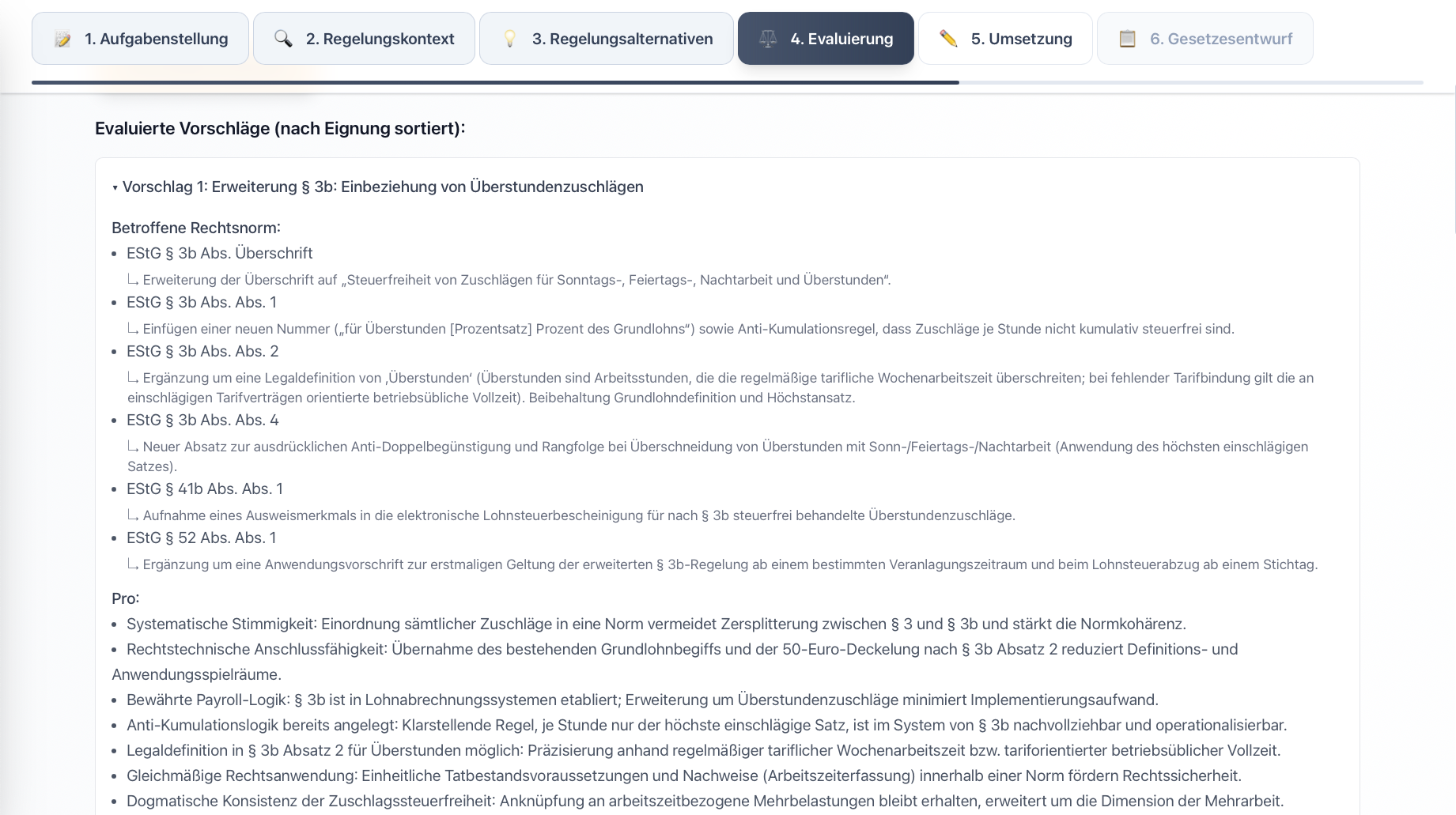
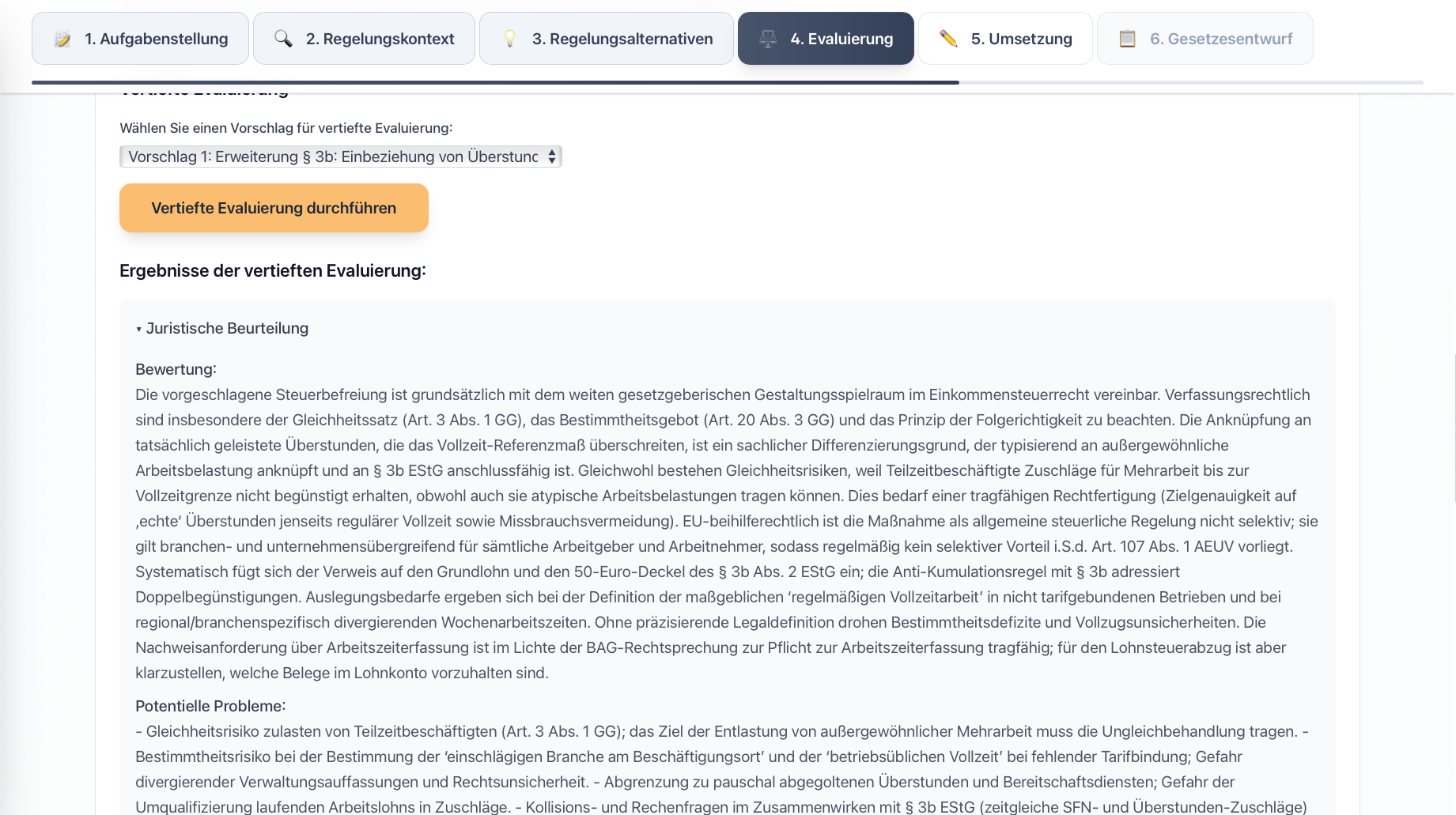
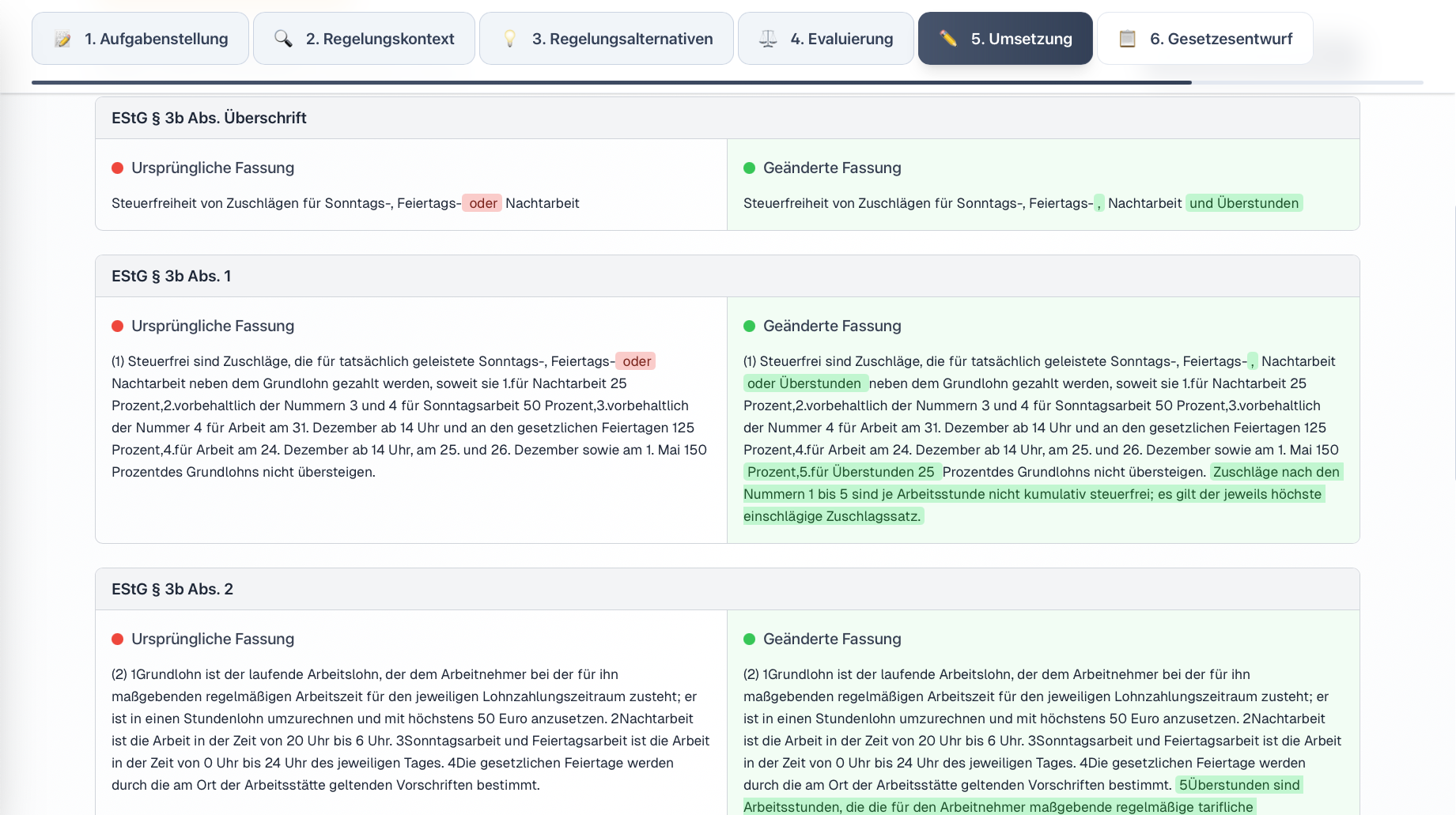
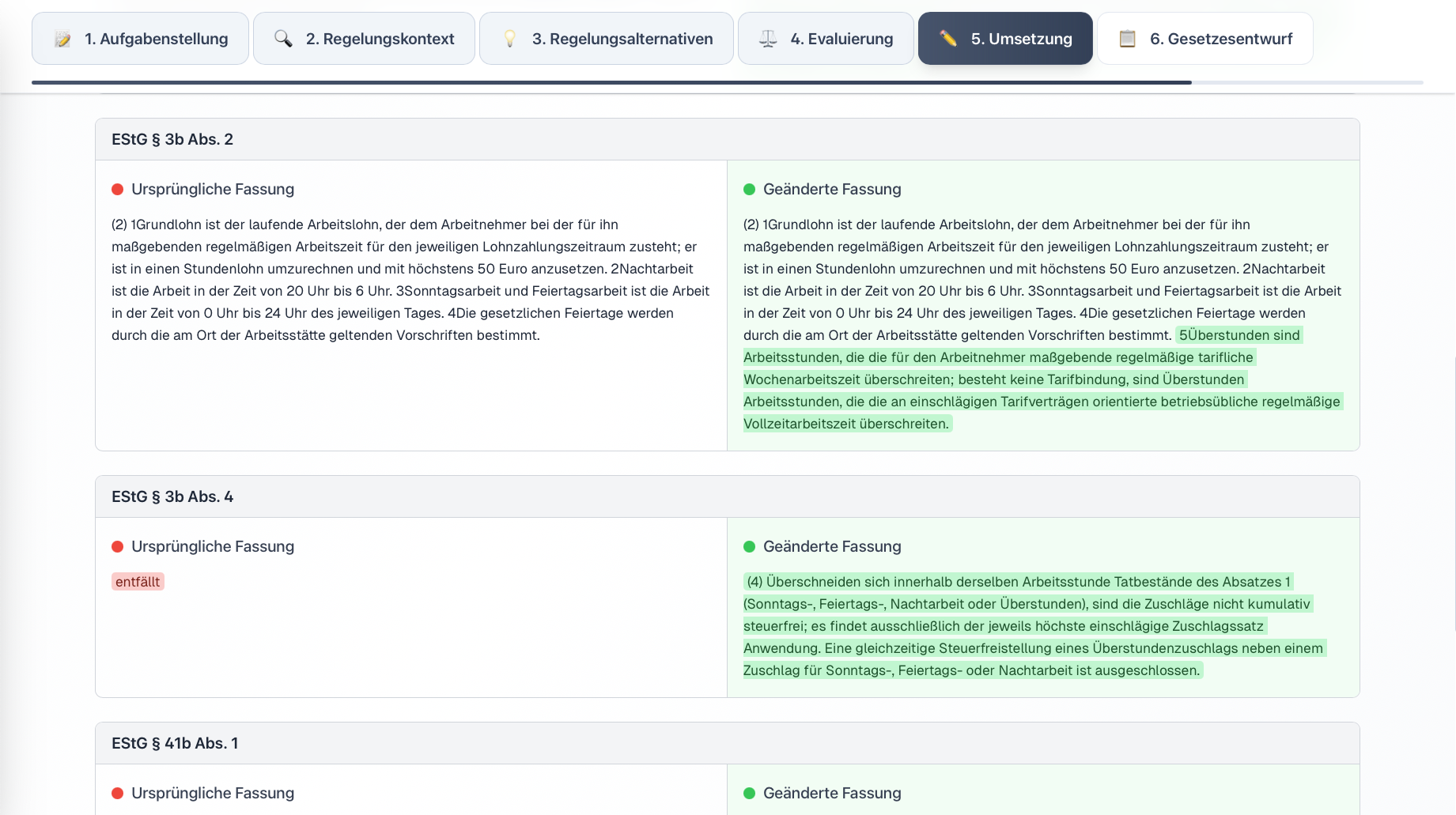
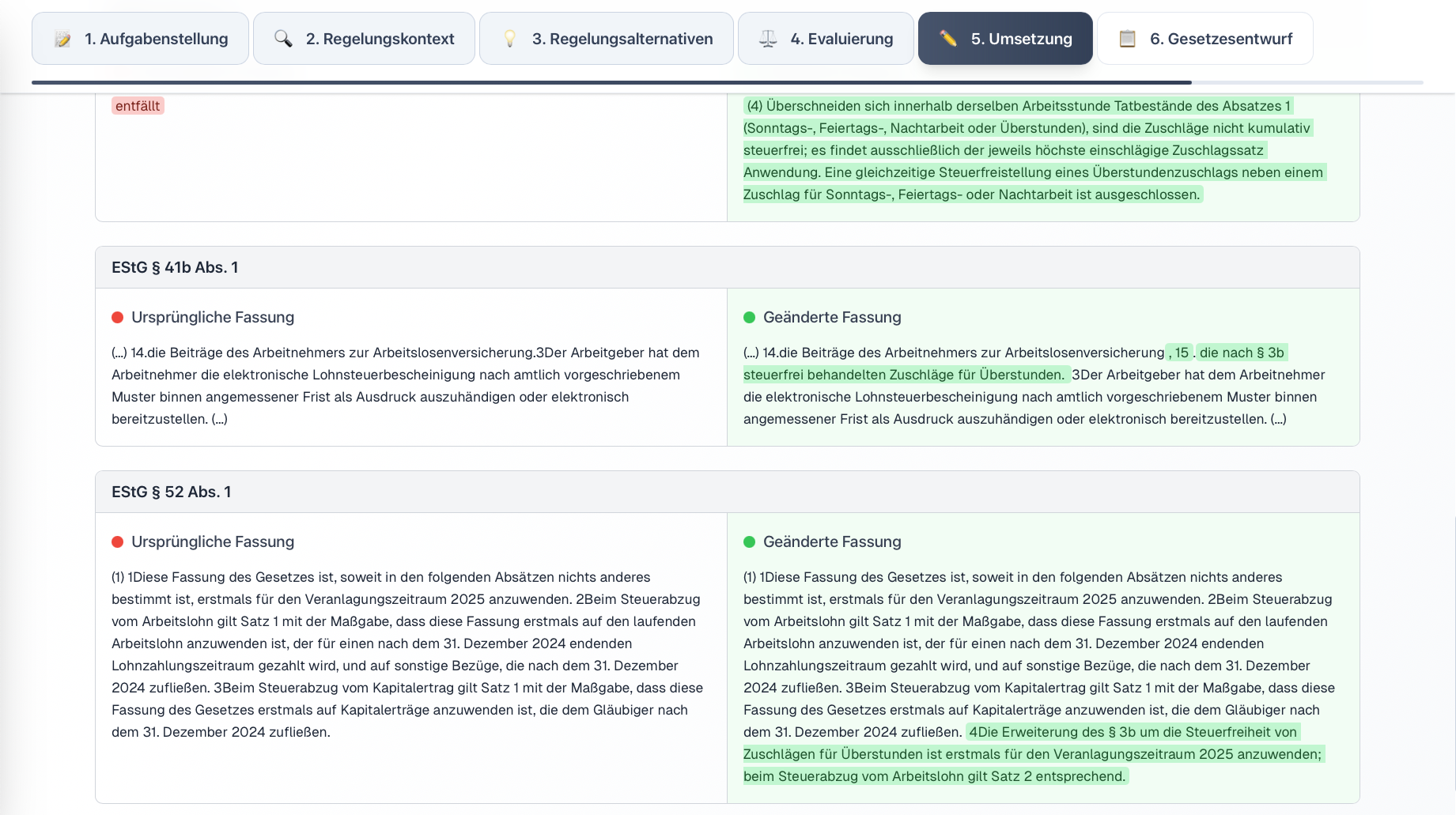
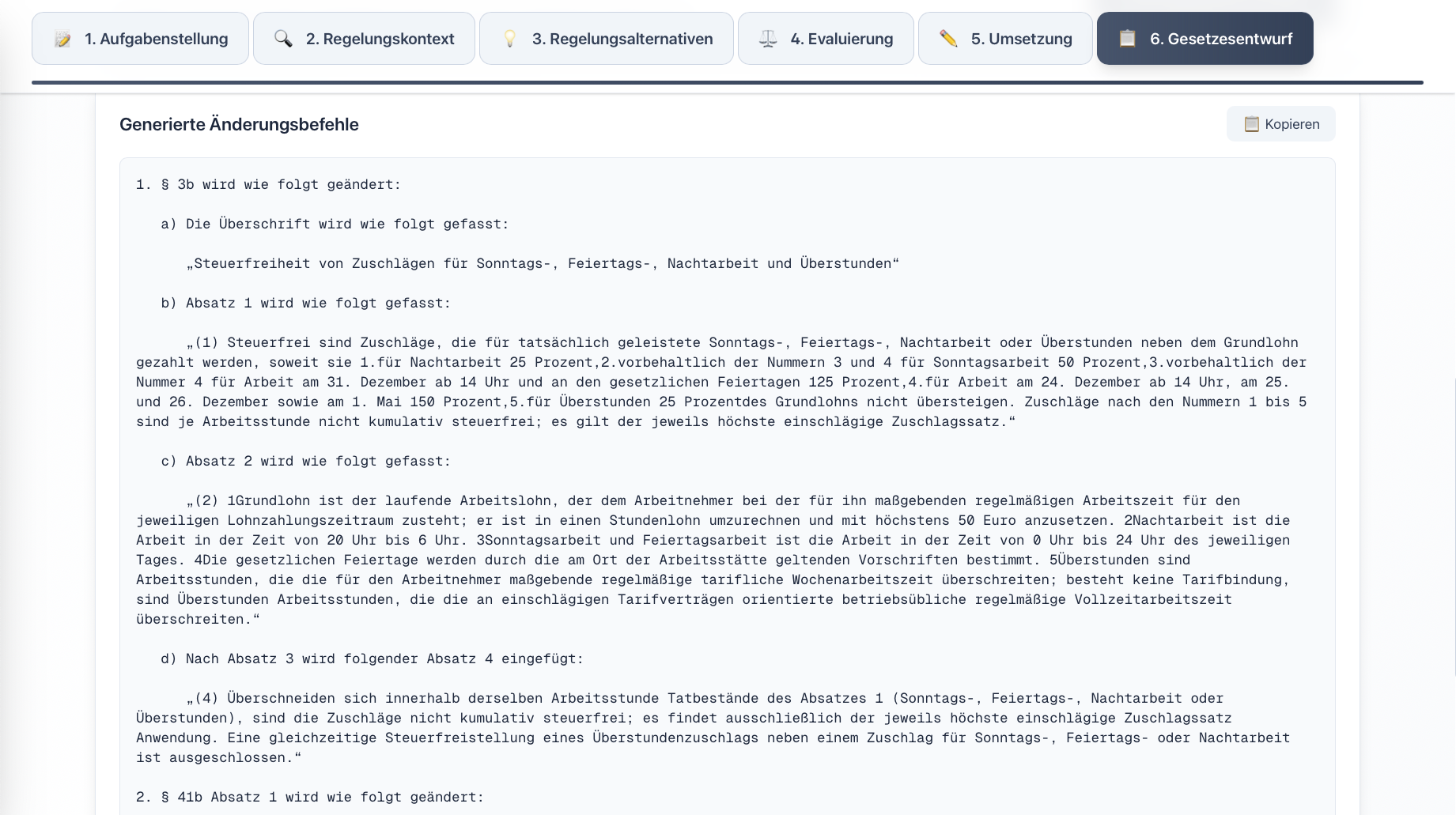
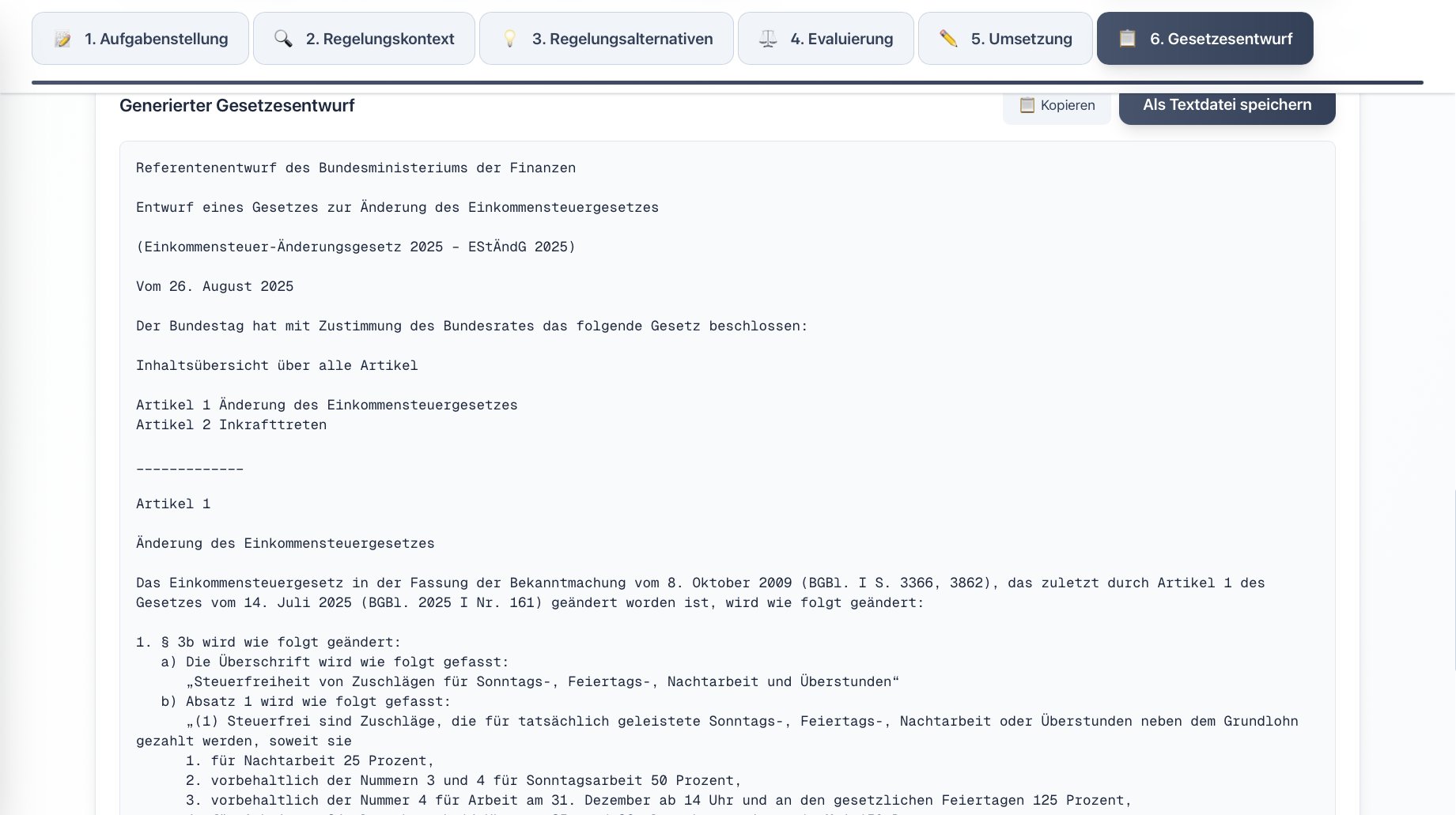
For more details, see our journal article in KIR 2025, 294 (published with the kind permission of C.H.Beck and the editorial team at KIR).
2) Automated Calculation of Compliance Costs
The assessment of compliance costs is a mandatory component of the legislative process in Germany. It quantifies the administrative burden that new regulations impose on citizens, businesses, and public administration. We are looking into NLP-based methods to automate and improve the calculation of compliance costs.
3) Contextualization of Law through Recognition of References
Legal texts are characterized by complex reference structures that connect provisions within and across different statutes. Analyzing explicit and implicit references between legal provisions, our research applies NLP-methods in combination with graph theory to map and visualize the network of legal relationships.